Racoons.ai
Find out why your website isn't bringing in customers

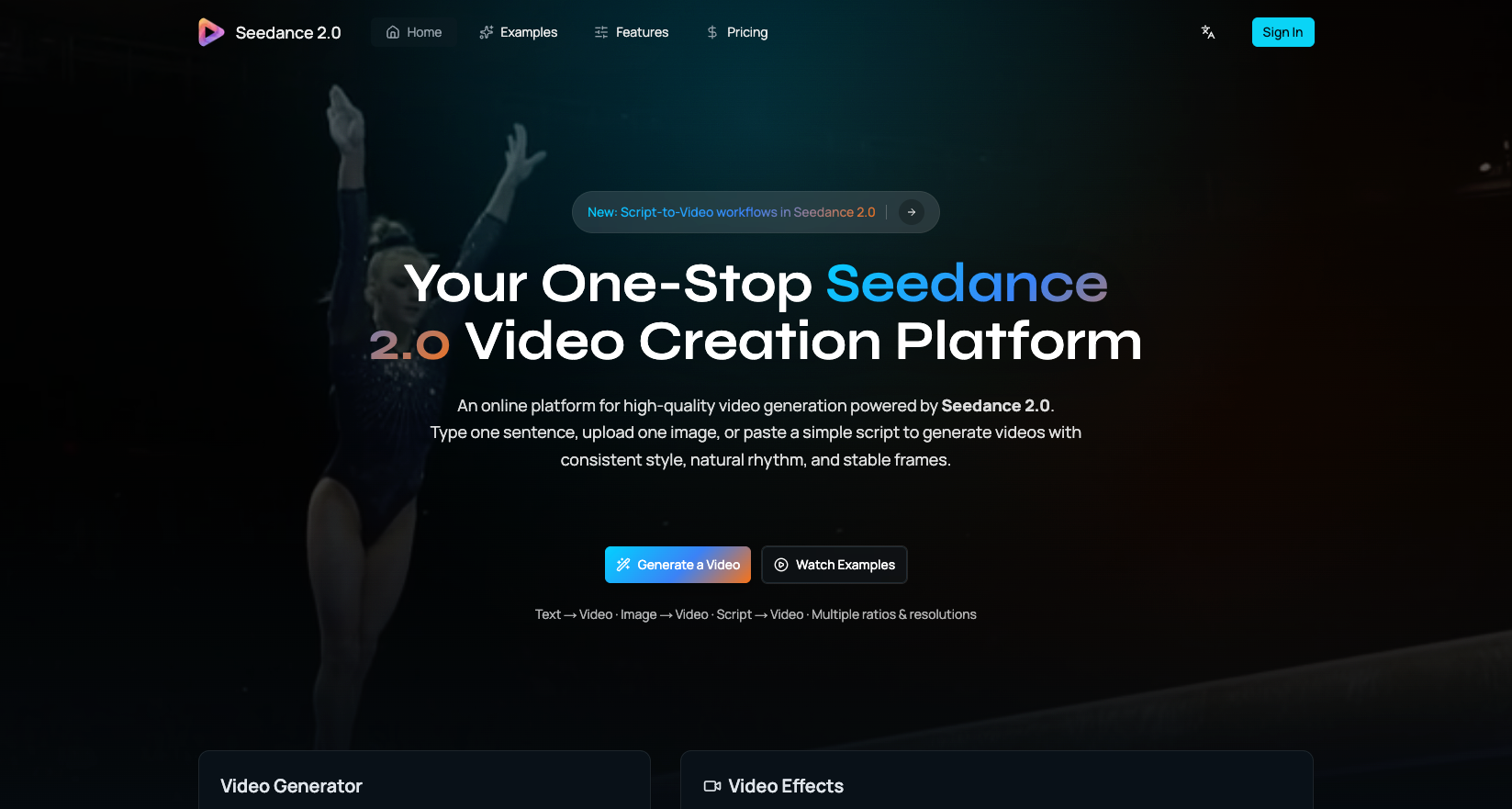
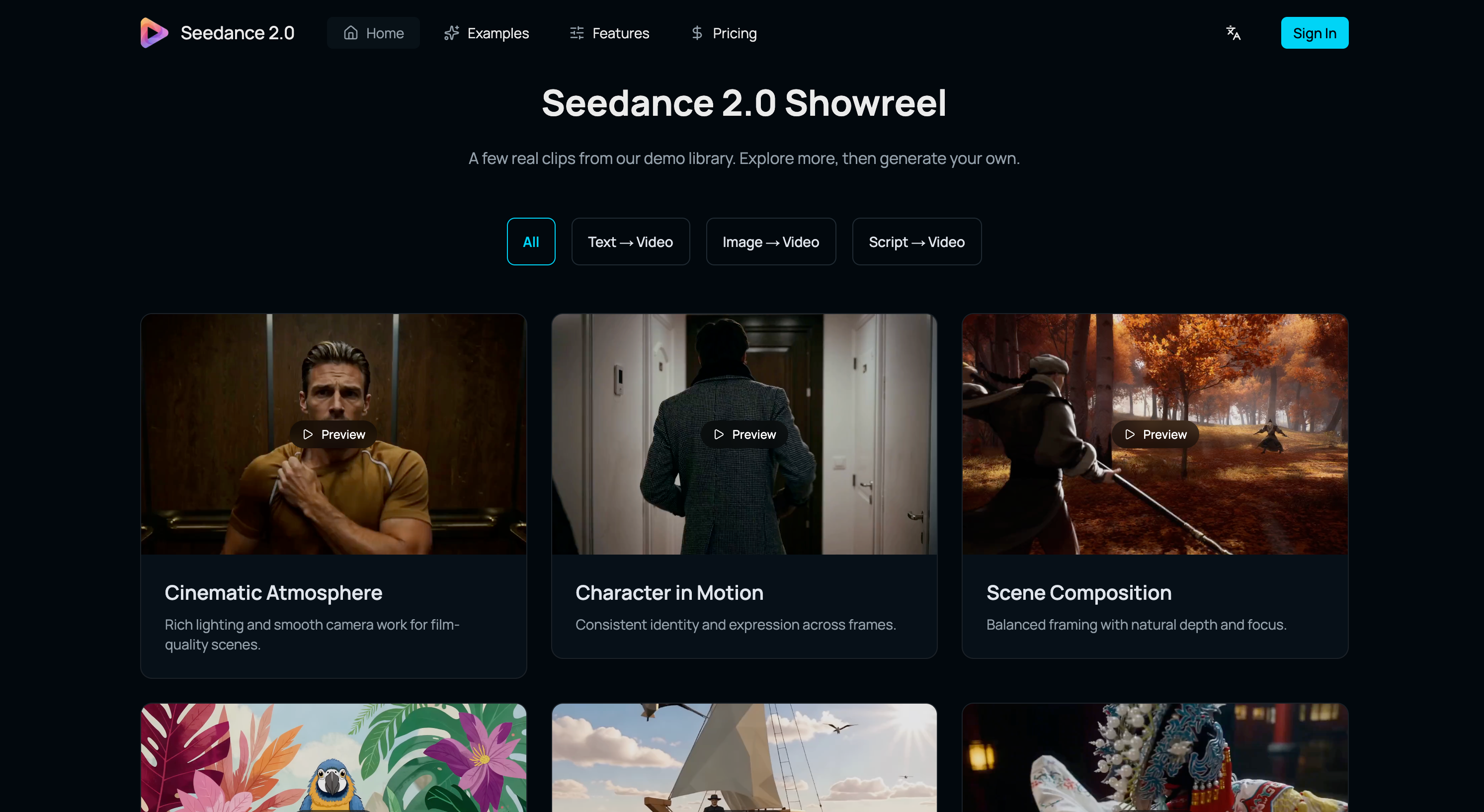
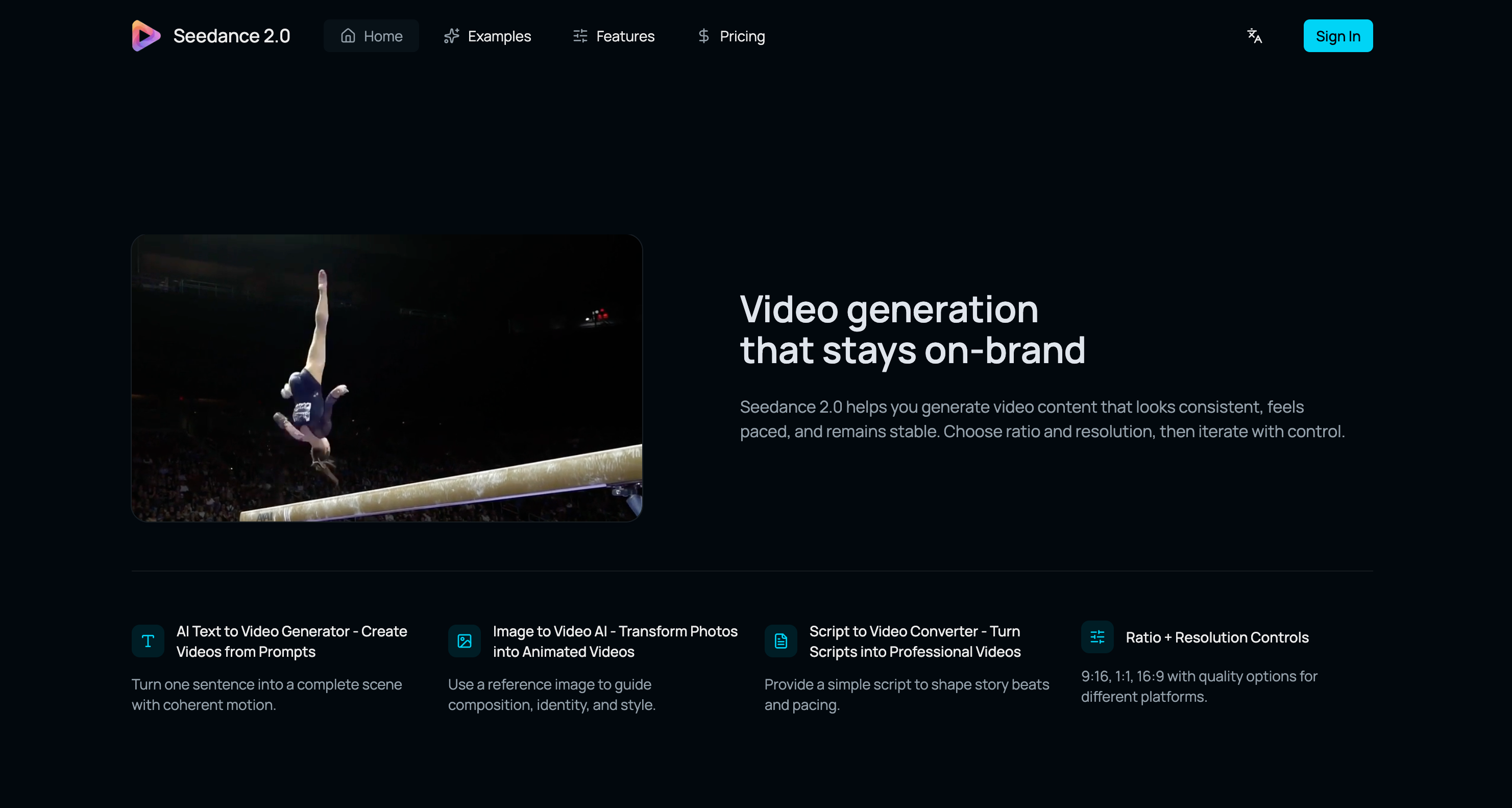
Turn prompts and images into high-quality AI videos

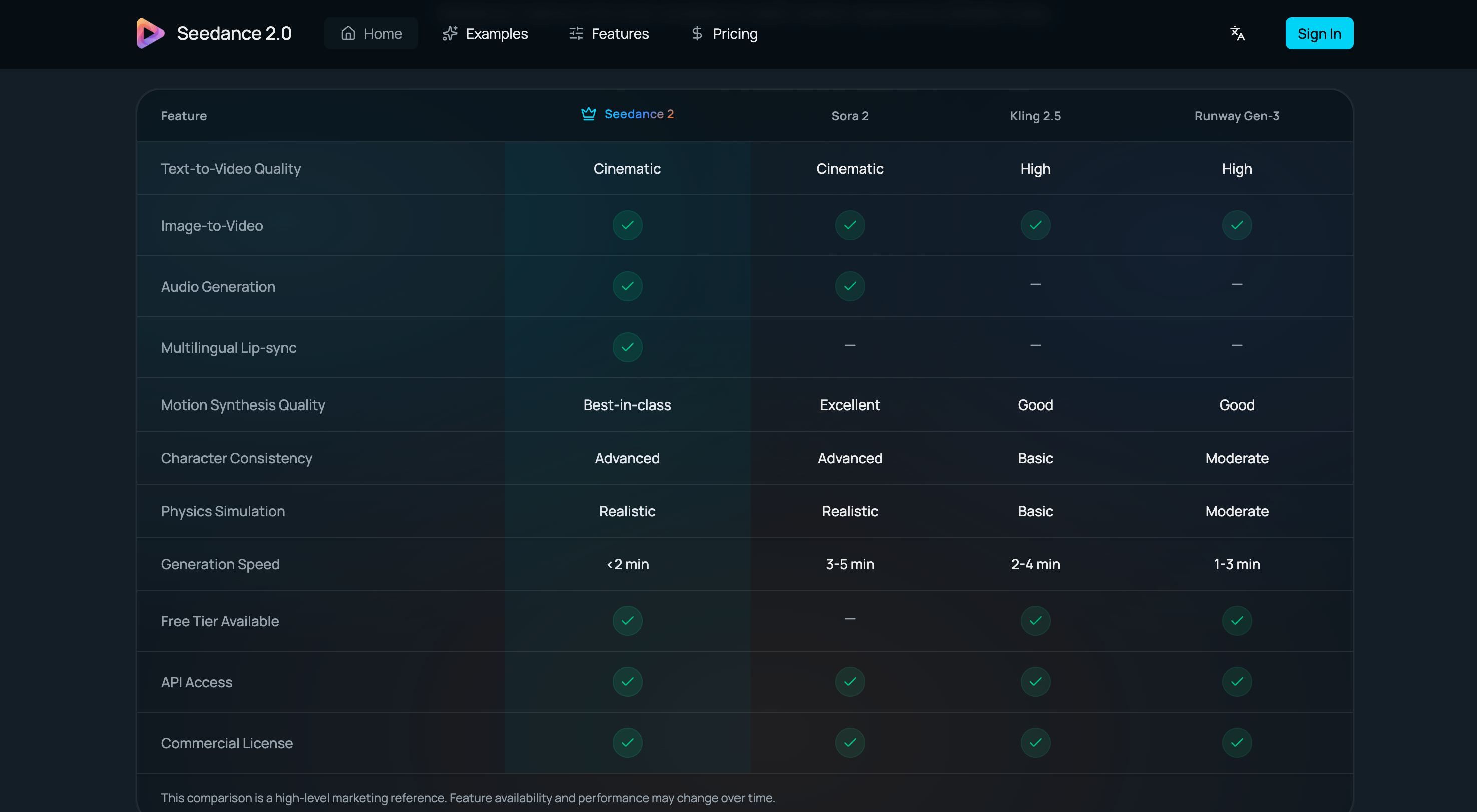
Seedance 2.0 is a web-based AI video generation platform developed by ByteDance's Seed research team that supports text-to-video and image-to-video workflows. It utilizes a diffusion transformer architecture to provide video output with synchronized audio and multilingual lip-sync capabilities.
Ideal for: Content creators, marketers, and designers seeking a tool to generate high-quality AI videos for social media reels, ad variations, and film pre-visualization.
No updates yet. Check back later for updates from the team.
No reviews yet. Be the first to rate this product!
Comments (0)
No comments yet. Be the first to share your thoughts!