
ICE - Infinite Context Engine
Site offlineInfinity. Within reach.
Details
- Follow on
- @dopove_aiLinkedIn
- Categories
- AIDeveloper ToolsArchitecture
- Target Audience
- B2B SaaS CompaniesEntrepreneursFounders & CEOs
- Pricing
- Freemium
- Platforms
- CLI
- Featured in
- Best Architecture
About ICE - Infinite Context Engine
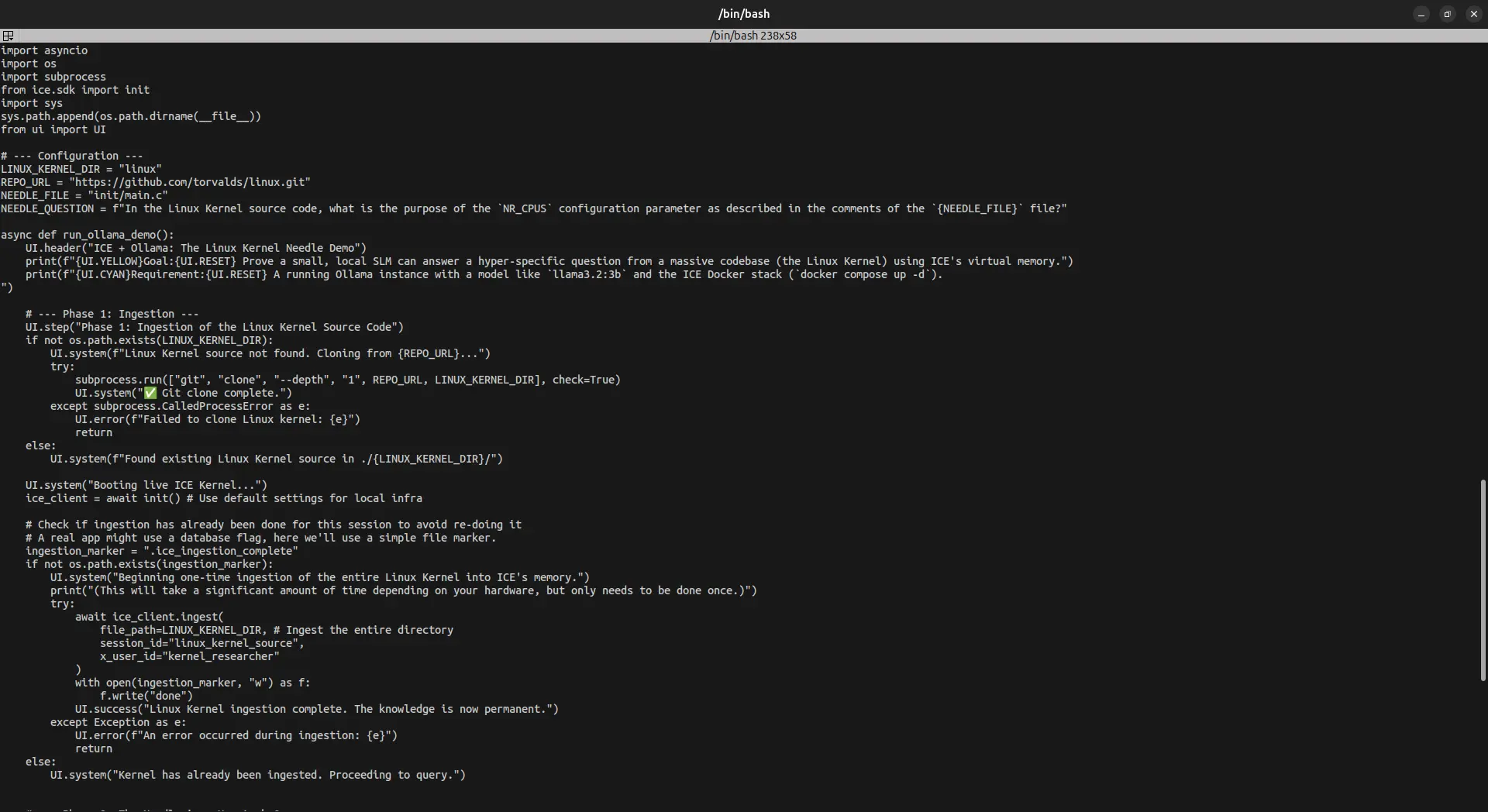
🧊 ICE by Dopove: The Virtual Memory Manager for LLMs Building AI agents is easy. Keeping them coherent in production is a nightmare. If you are building long-lived agents or enterprise copilots, you’ve likely hit the same wall: the LLM works perfectly in the demo, but degrades in production because it can’t reliably hold, retrieve, and attend to the right context over a long workflow. Right now, most teams respond by duct-taping together a custom memory stack—Postgres + pgvector + Redis + session IDs + summarization loops. It’s fragile, expensive to debug, and leads to specific, bleeding-neck failures: Agents hit Step 10 and forget the tool output from Step 2. You shove more context into the prompt, your token bills explode, and the model still suffers from "Lost in the Middle" amnesia. You live in constant fear of multi-tenant data leakage. Try ICE (Infinite Context Engine). ICE is a drop-in Virtual Memory Management (VMM) layer that sits between your existing application and any upstream LLM (OpenAI, Anthropic, Gemini, Ollama). The best part? Zero migration friction. ICE is 100% API compatible. You literally just change your base URL. You keep your SDKs, your prompts, and your orchestration frameworks (LangGraph, LlamaIndex, etc.). What ICE handles under the hood: Cures Agentic Amnesia: ICE natively understands tool calls. It pins critical, recent tool-results to the active window and safely archives older steps to a Semantic Ledger. Multi-step agents never lose their train of thought. BYODB (Bring Your Own Database): Don't migrate your data. Point ICE at your existing PostgreSQL (pgvector) and Redis clusters. You own the storage and the infrastructure; we just provide the memory OS. Glass-Box Observability: Engineers hate black boxes. ICE natively exports OpenTelemetry (OTel) traces and includes a dry-run API. You can see the exact token receipts and injected context before it ever hits the LLM. You never lose control of the prompt. Precision Paging: We don't do dumb summarization. ICE dynamically pages raw, high-signal context into the prompt exactly when the agent needs it, keeping your physical token count ruthlessly low while guaranteeing perfect historical recall. Kernel-Level Multi-Tenancy: Isolation isn't an app-level afterthought. ICE enforces multi-tenancy at the database layer via PostgreSQL Row-Level Security (RLS). Cross-tenant leakage is mathematically impossible. Sovereign / VPC Deployment: Built for regulated enterprises where your data and memory state cannot leave your own boundary. Planned Future Features: We are actively building the next generation of LLM physics to completely eliminate token bottlenecks and compute waste. True Infinite Input (Zero-Token Cost): We are moving beyond text prompts. ICE is developing direct KV-Cache memory mapping. Soon, models won't "read" context; ICE will inject it directly into the model's neural state, unlocking instant 100-Billion token horizons with zero input API costs. Multi-Tenant Batch Routing: To slash enterprise inference bills, ICE will aggregate queries across your entire application and process them in single, massive inference batches—while using our strict VMM isolation to guarantee tenant data never crosses streams. Hardware Defiance: Our ultimate goal is O(1) memory mapping efficiency, allowing you to run 1,000 concurrent, memory-dense AI sessions on a single edge device without degrading performance. We are members of the NVIDIA Inception Program. If you are shipping persistent enterprise copilots or multi-tenant AI products, stop rebuilding brittle Postgres/Redis memory workarounds. Read the docs, contact us, and drop ICE into your stack today: 👉 https://dopove.com/ice
Product Insights
ICE acts as a Virtual Memory Management layer for AI agents, providing API compatibility with major LLMs while handling persistent state via existing databases. It enables long-term coherence through semantic paging and architectural features like OpenTelemetry and Row-Level Security.
- Drop-in API compatibility with major LLMs such as OpenAI, Anthropic, and Gemini.
- Native multi-tenancy enforcement through PostgreSQL Row-Level Security (RLS).
- Bring Your Own Database (BYODB) support for existing PostgreSQL and Redis clusters.
- Integrated OpenTelemetry (OTel) exports for full prompt and context observability.
Ideal for: B2B SaaS Companies, Entrepreneurs, and Founders & CEOs building persistent AI agents that require strict data isolation and long-term context recall.
Screenshots
Reviews (0)
No reviews yet. Be the first to rate this product!
Comments (1)
We built ICE after watching teams spend 60% of engineering time on memory plumbing instead of their actual product. One import replaces the entire stack. Curious what you're building?