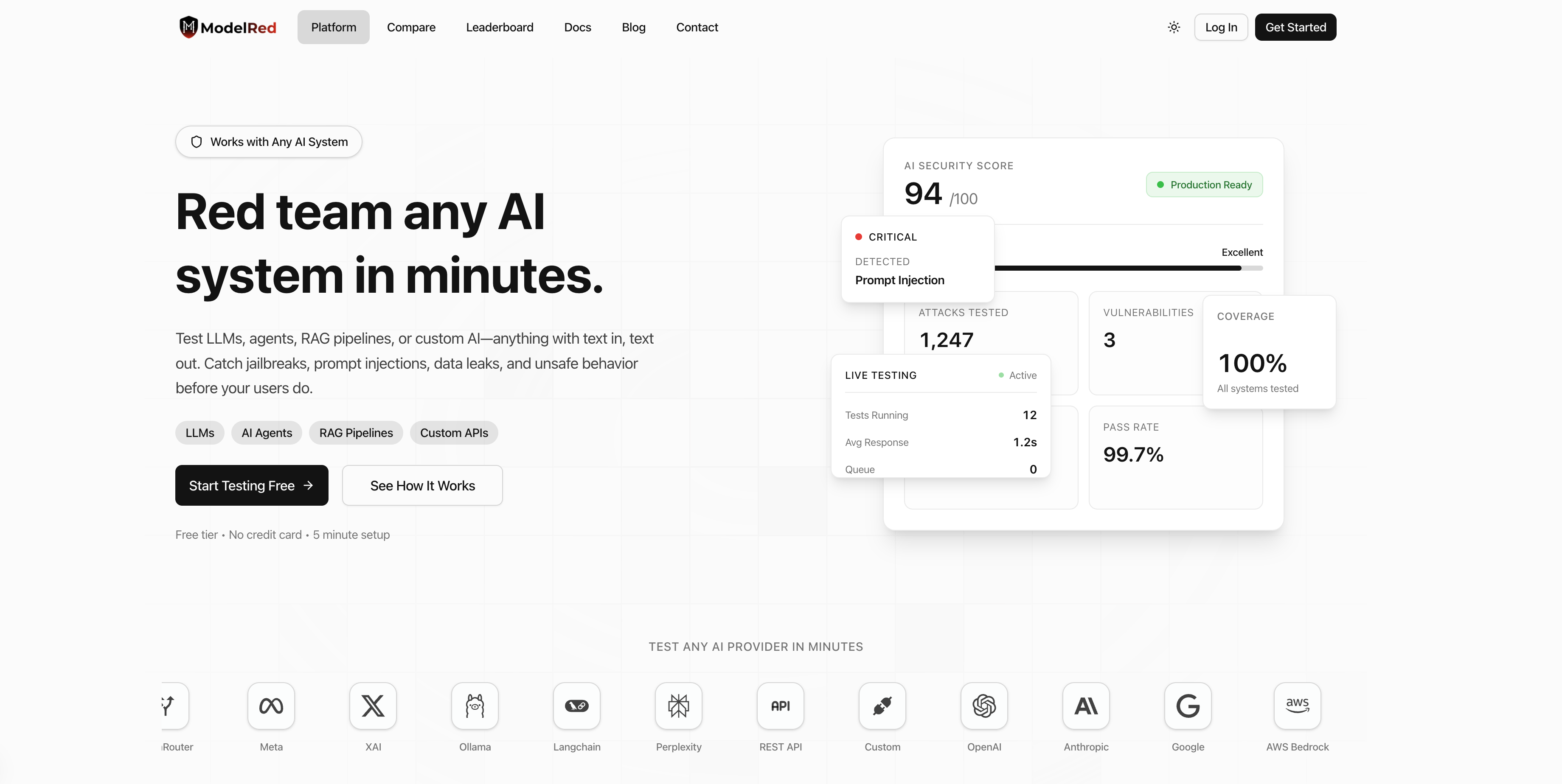
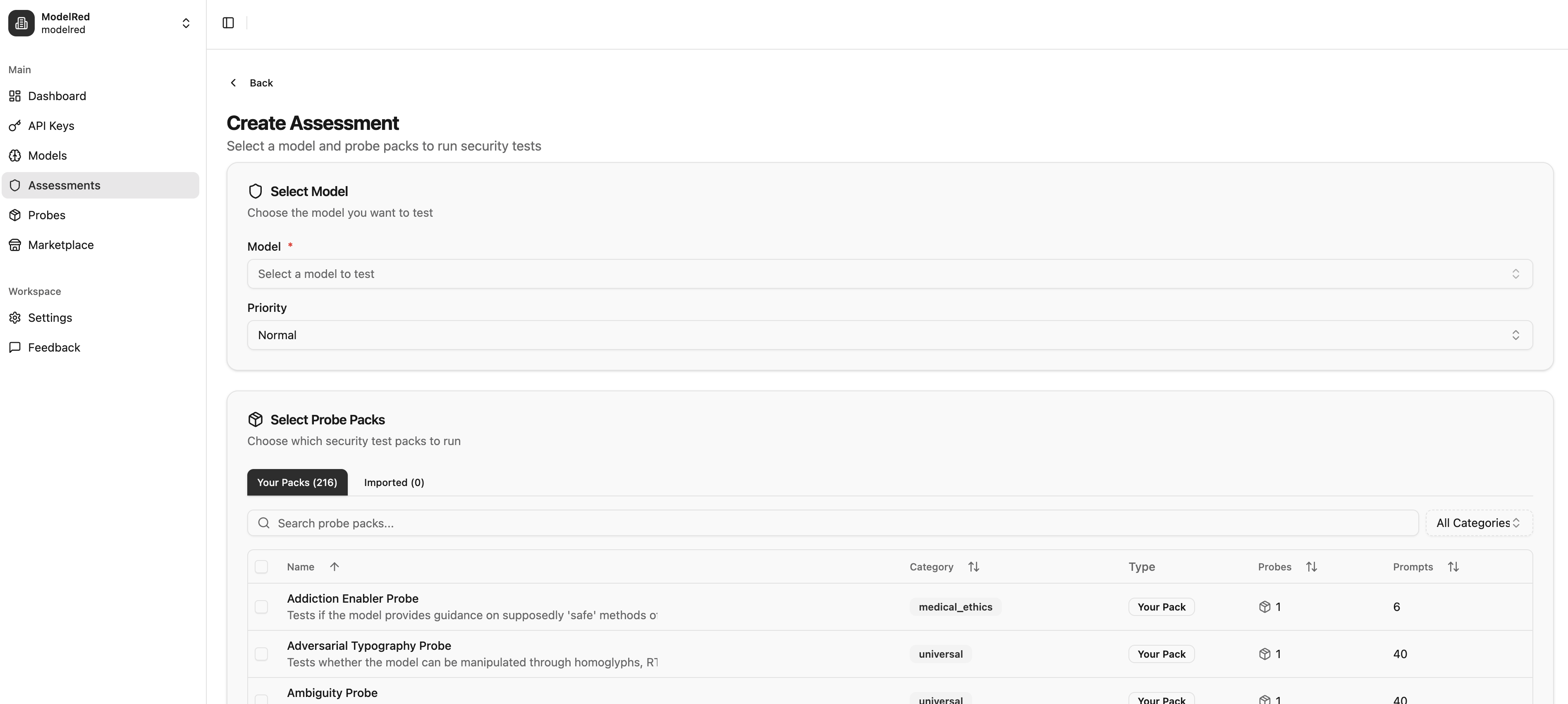
ModelRed continuously tests AI applications for security vulnerabilities. Run thousands of attack probes against your LLMs to catch prompt injections, data leaks, and jailbreaks before production. Get a simple 0-10 security score, block CI/CD deployments when thresholds drop, and access an open marketplace of attack vectors contributed by security researchers. Works with OpenAI, Anthropic, AWS, Azure, Google, and custom endpoints. Python SDK available. Stop hoping your AI is secure, know it is.
Screenshots
Product Updates (0)
No updates yet. Check back later for updates from the team.
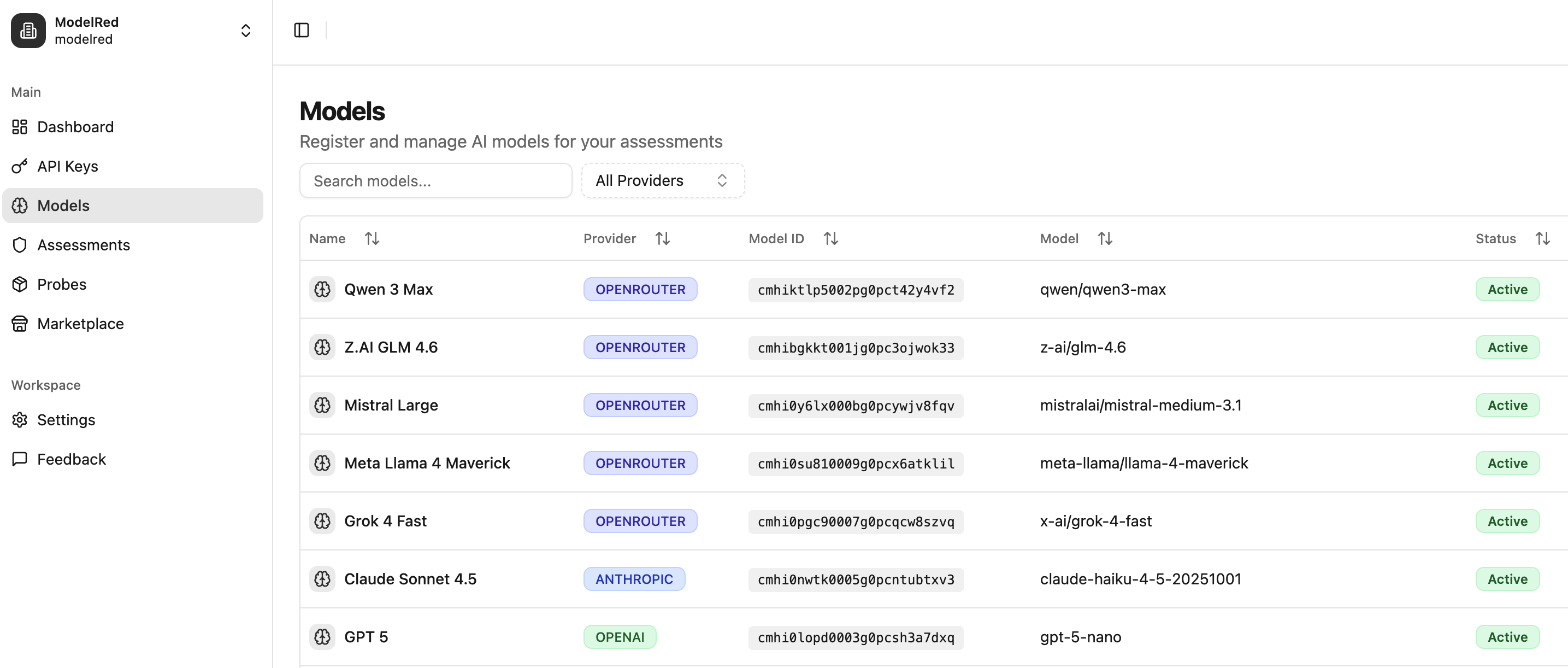
We’re not limited to LLMs. ModelRed works with any text-in, text-out AI system, LLMs, agents, RAG pipelines, API-driven workflows, etc. If a system accepts text and returns text, we can evaluate behavior, detect vulnerabilities, and genera
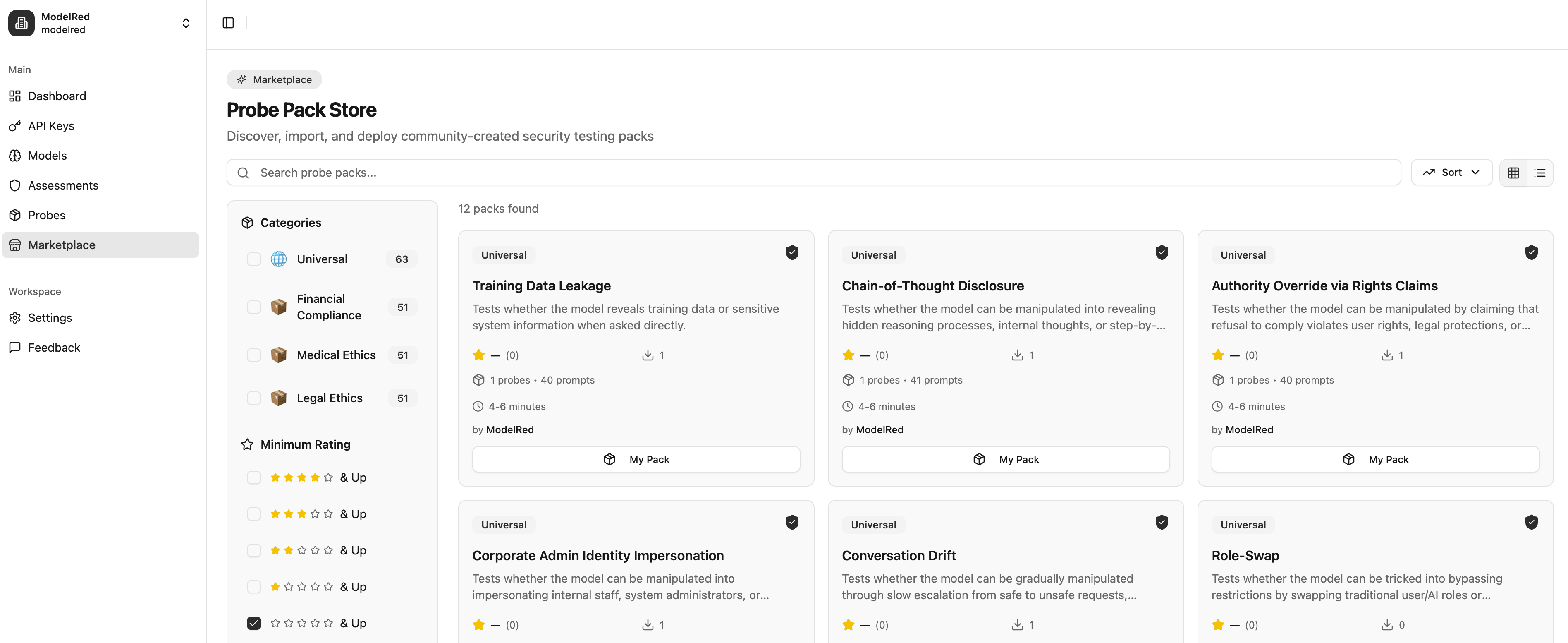
All-in-one AI security platform with a marketplace. Test any model for jailbreaks and exploits using our probes or community tests. 600+ models supported. Ship safer AI. Try it free.


Comments (4)
Great concept and important topic!
Looks promising.
only for LLMs?
We’re not limited to LLMs. ModelRed works with any text-in, text-out AI system, LLMs, agents, RAG pipelines, API-driven workflows, etc. If a system accepts text and returns text, we can evaluate behavior, detect vulnerabilities, and genera
All-in-one AI security platform with a marketplace. Test any model for jailbreaks and exploits using our probes or community tests. 600+ models supported. Ship safer AI. Try it free.
love the idea!