
Repo Watch
Scan repositories for risk scores and code quality
Details
- Follow on
- Target Audience
- DevelopersDevOps EngineersFounders & CEOs
- Pricing
- Freemium from $29
- Platforms
- Web
About Repo Watch
Repo Watch allows you to scan any repository to get a clear risk score in minutes. You can evaluate tests, code quality, dependencies, and identify potential red flags before shipping your code.
Product Insights
Repo Watch is a web-based repository scanning tool that provides risk scoring and code quality metrics for developers and DevOps engineers. It features a complexity risk score that detects performance scaling issues, baseline tracking for score drift, and support for custom test coverage artifacts.
- Freemium pricing model with paid tiers starting at $29.
- Detection of performance scaling risks via complexity risk scoring without code execution.
- Comprehensive reporting tools available in both PDF and Markdown formats.
- Customizable finding tracking to manage false positives across sequential repository scans.
Ideal for: Developers and DevOps engineers who need to monitor code quality and security risks across web repositories through automated scoring and baseline drift tracking.
Product Video
Watch a video demo of Repo Watch.
Screenshots
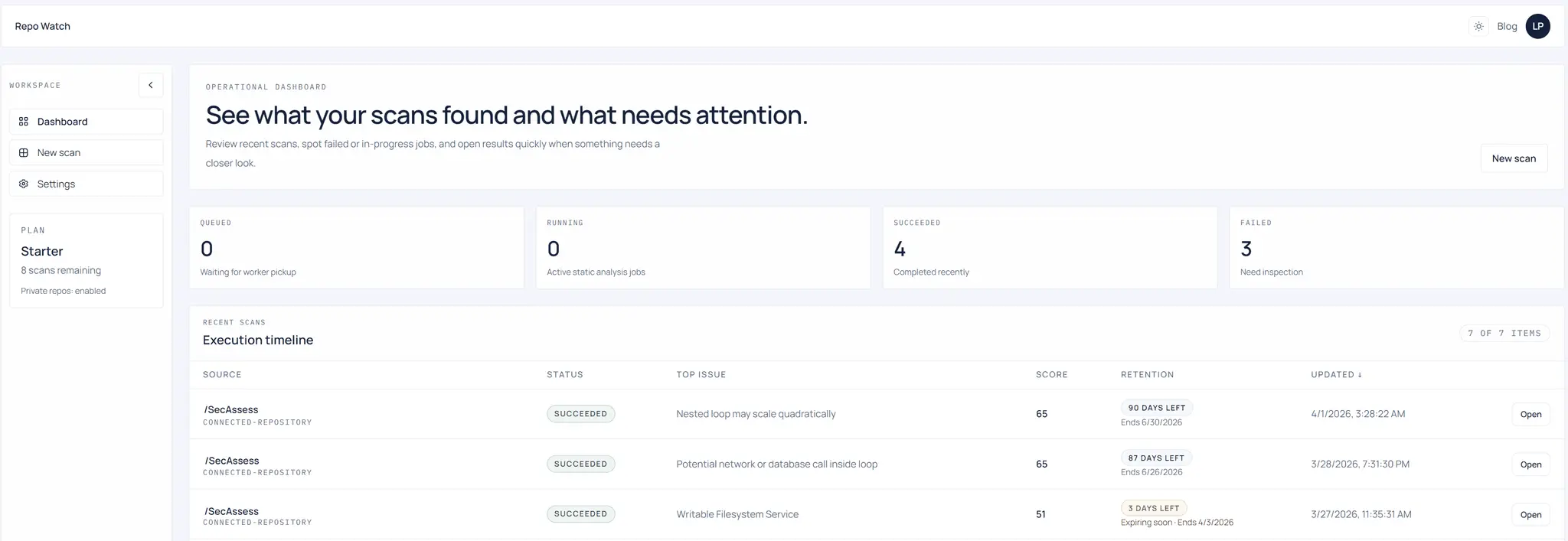
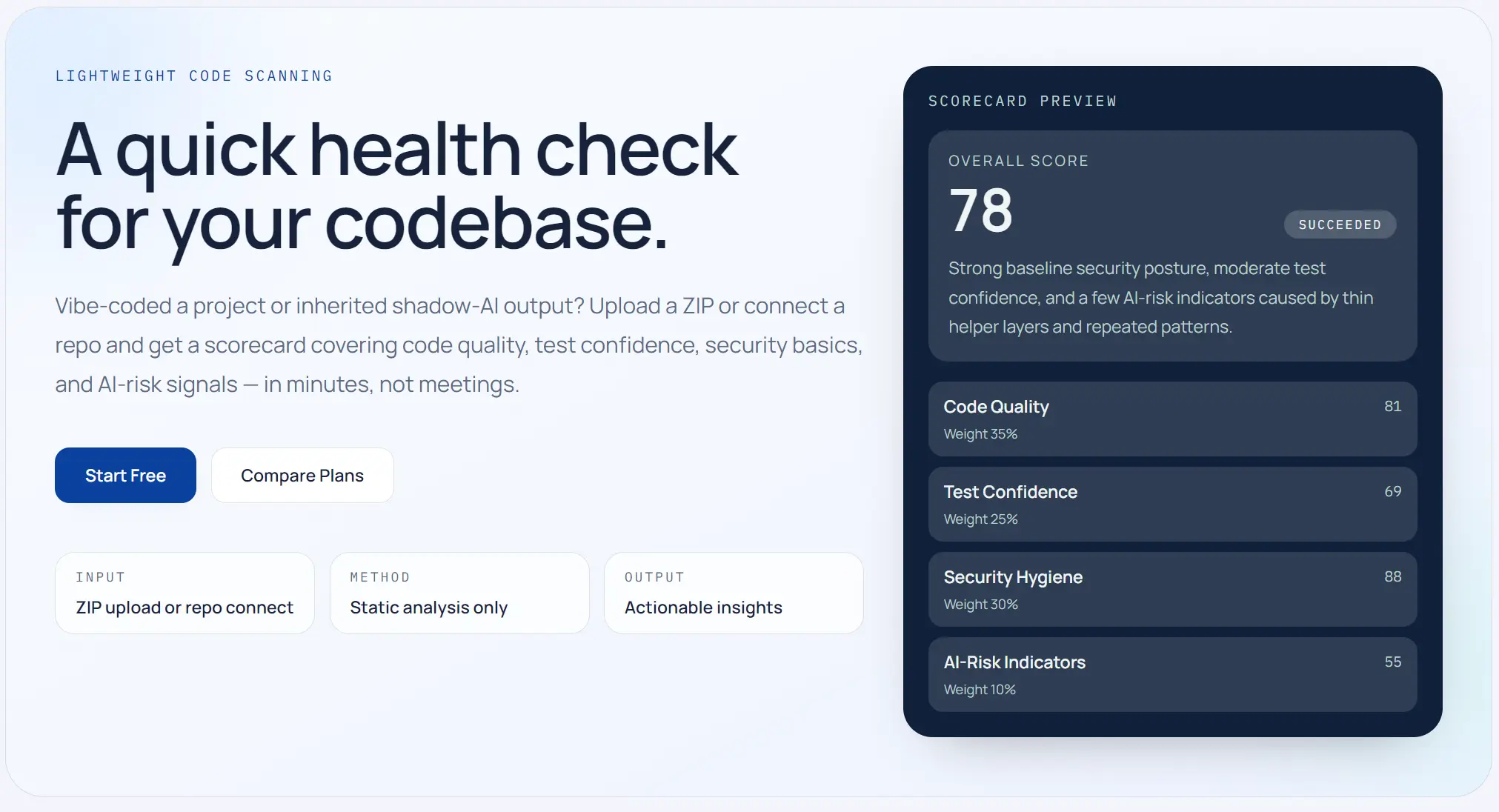
Product Updates (2)
Community Feedback coming in
Huge thank you to everyone sharing feedback with me over email and other channels. It’s directly shaping Repo Watch. Since the last update, we’ve shipped a lot: - Compare scans with baseline score tracking so you can see drift scan-to-scan - Support for user-provided test coverage artifacts across different language stacks - “Intentional” finding tracking for false positives in your own context across scans - Next iteration of downloadable reports (PDF + Markdown), now including score drift between scans - Free tier update: all individual findings are now visible, not just grouped findings There’s much more coming. The long-term vision for Repo Watch is simple: “I inherited this repo. Tell me what to fix first this week, and prove whether risk is moving up or down over time.” https://repowatch.io/releases
Comments (1)
v0.2.0: complexity risk scoring released!
In my latest update i share how we got up in running over just 9 days. https://repowatch.io/blog/repowatch-week-one-what-we-built You can read about all the features we released and how the latest Complexity Risk Score works. How Complexity Risk Score works Complexity Risk measures how likely a codebase is to have performance scaling problems — without executing any code. The scanner reads every source file and uses pattern matching to detect common code shapes that tend to slow down as data grows: Nested loops (loop inside a loop) — flagged as O(n²), "grows fast" Linear search inside a loop (.find/.filter/.includes in a loop body) — also O(n²) Sorting inside a loop — O(n log n), "moderate growth" Network/DB calls inside a loop (fetch, prisma, etc.) — O(n), scales linearly with data Each detected pattern gets a fixed risk rating (72–92), a complexity class label, a 4-line code snippet, and a language-specific refactoring suggestion. The top 3 worst findings drive the score — starting from a perfect 100 and deducting 6–20 points each based on severity, with a small extra penalty if more than 3 hotspots exist. When nothing is found, the panel flips to green "all clear" signals for each pattern category. Complexity Risk contributes 10% of the overall repo health score, alongside Code Quality (30%), Test Confidence (25%), Security Hygiene (25%), and AI Risk Indicators (10%).
Reviews (0)
No reviews yet. Be the first to rate this product!
Comments (1)
I built RepoWatch for a problem I kept seeing over and over: codebases that run, people depend on them, but nobody is fully confident owning them. I'd love to get feedback so please reach out.