
Sifter
Your documents are a dark database
Details
- Follow on
- Categories
- Open Source
- Target Audience
- Data ScientistsOperations ManagersEnterprises
- Pricing
- Freemium from $19
- Platforms
- Web
About Sifter
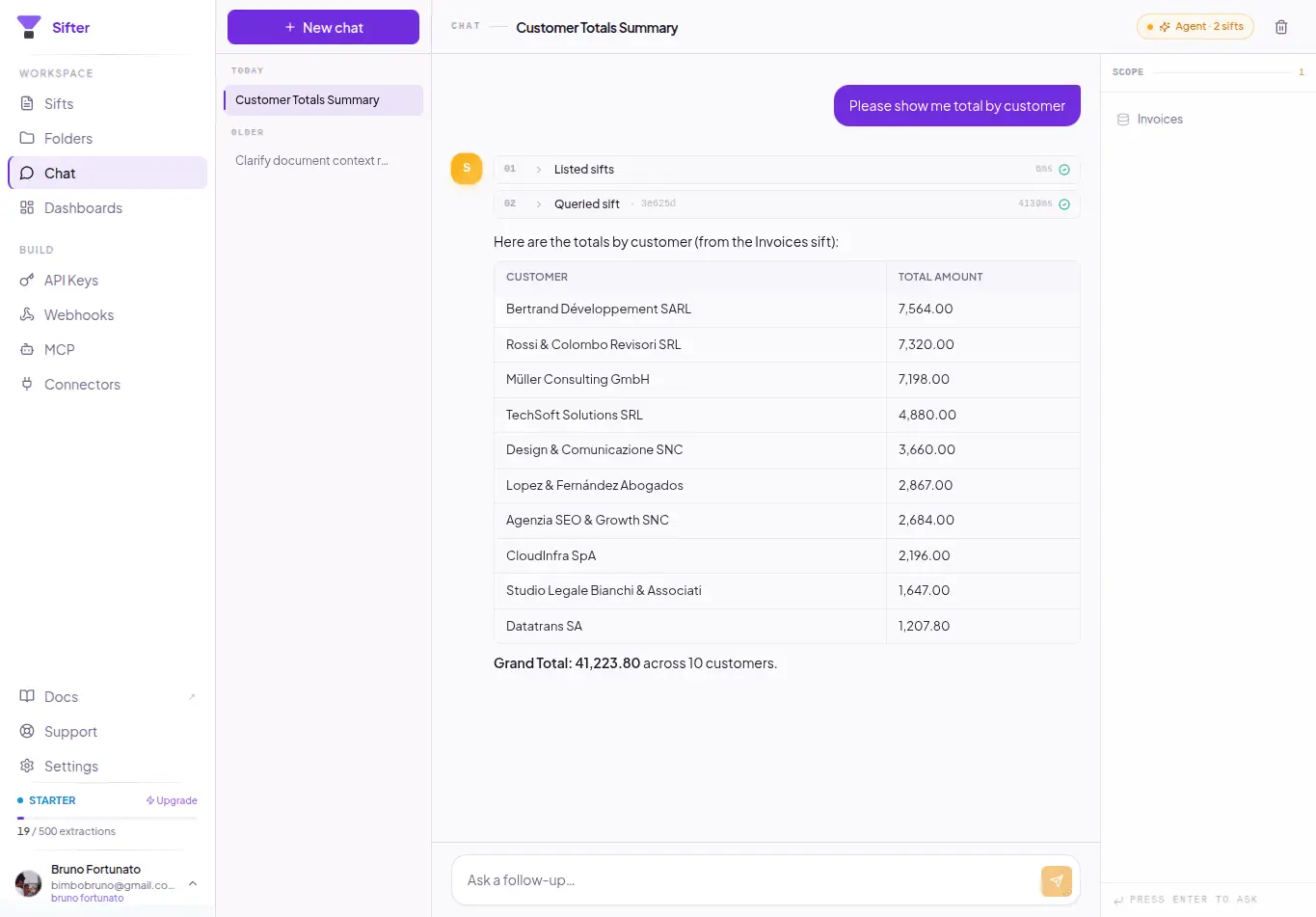
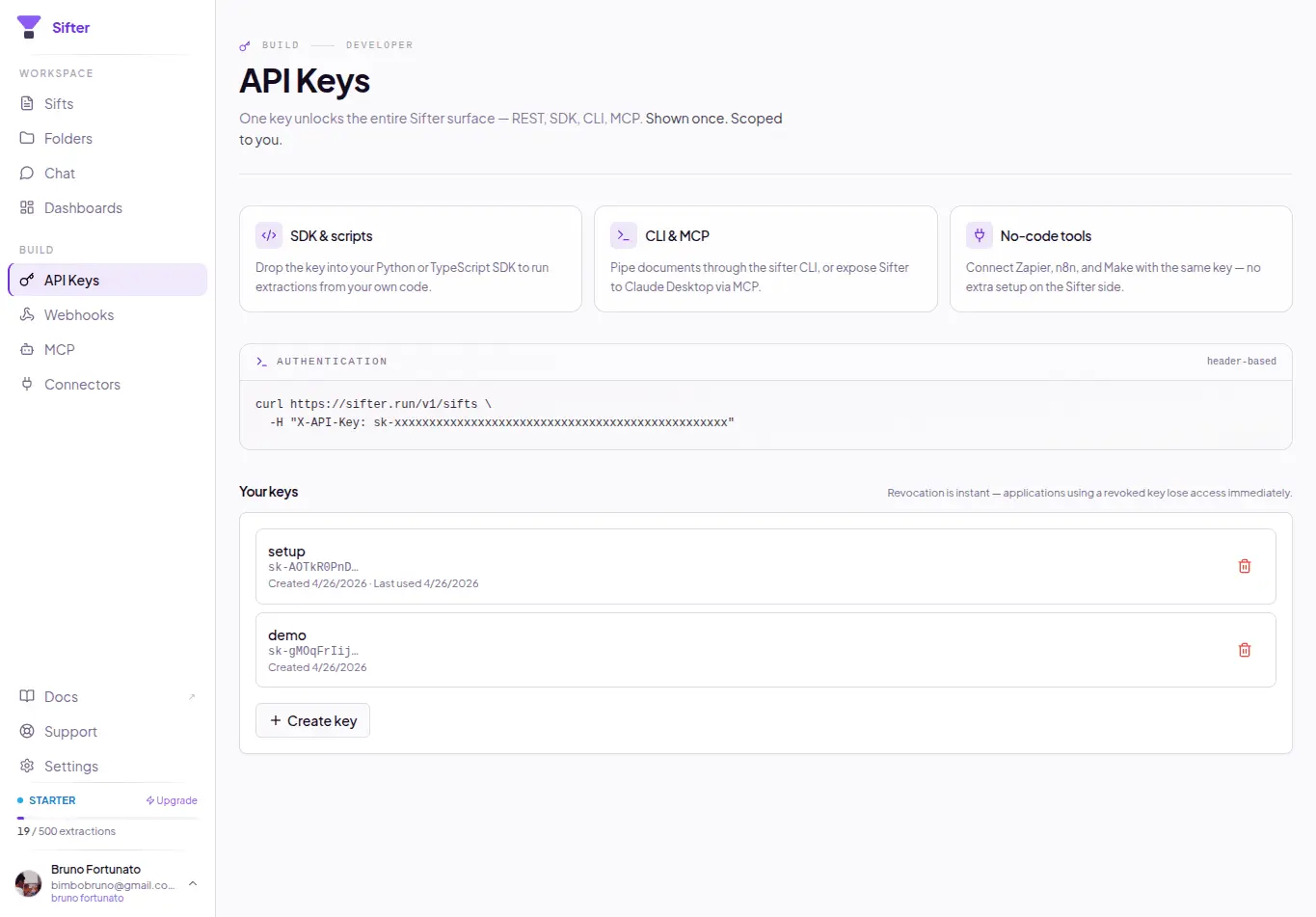
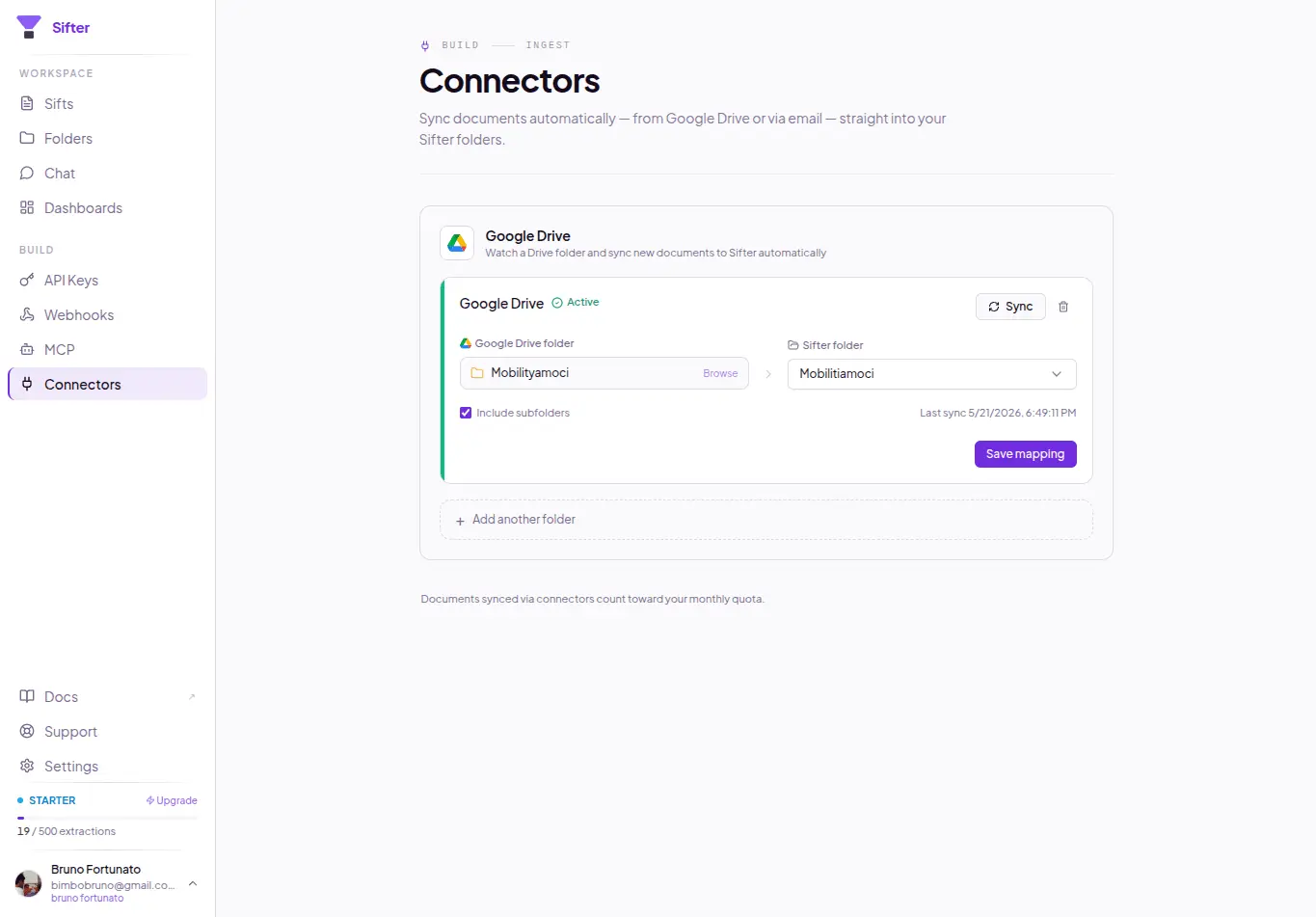
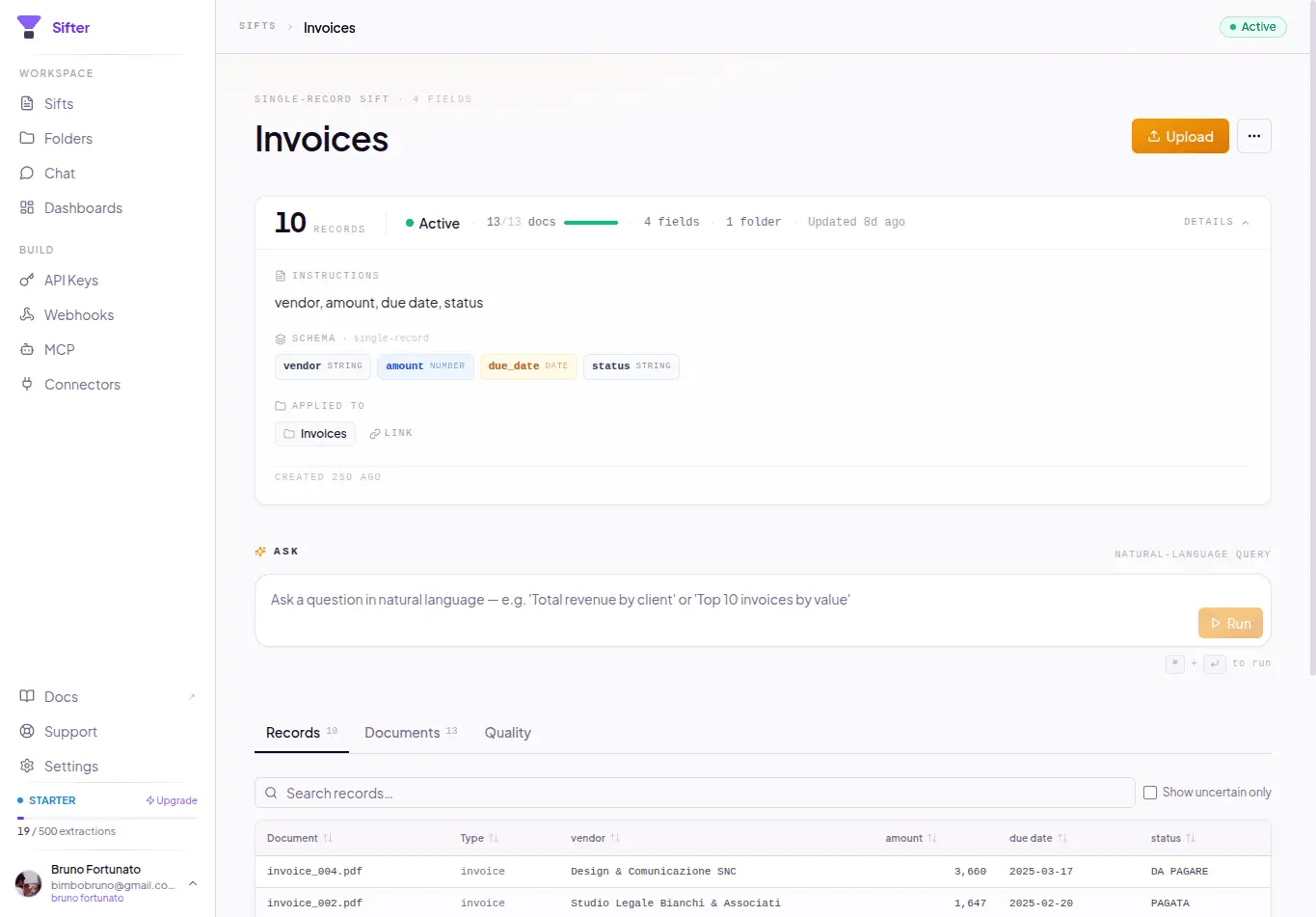
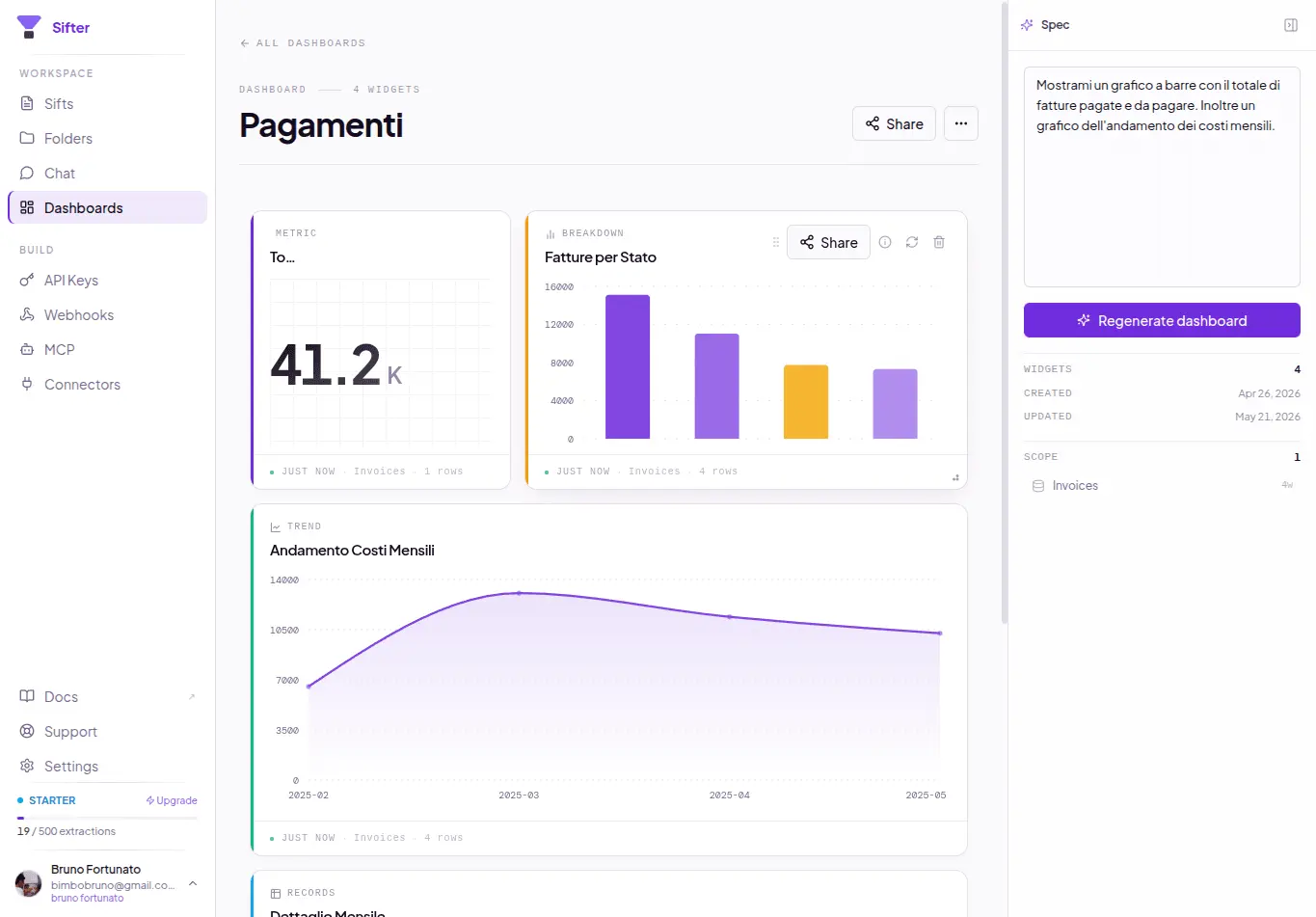
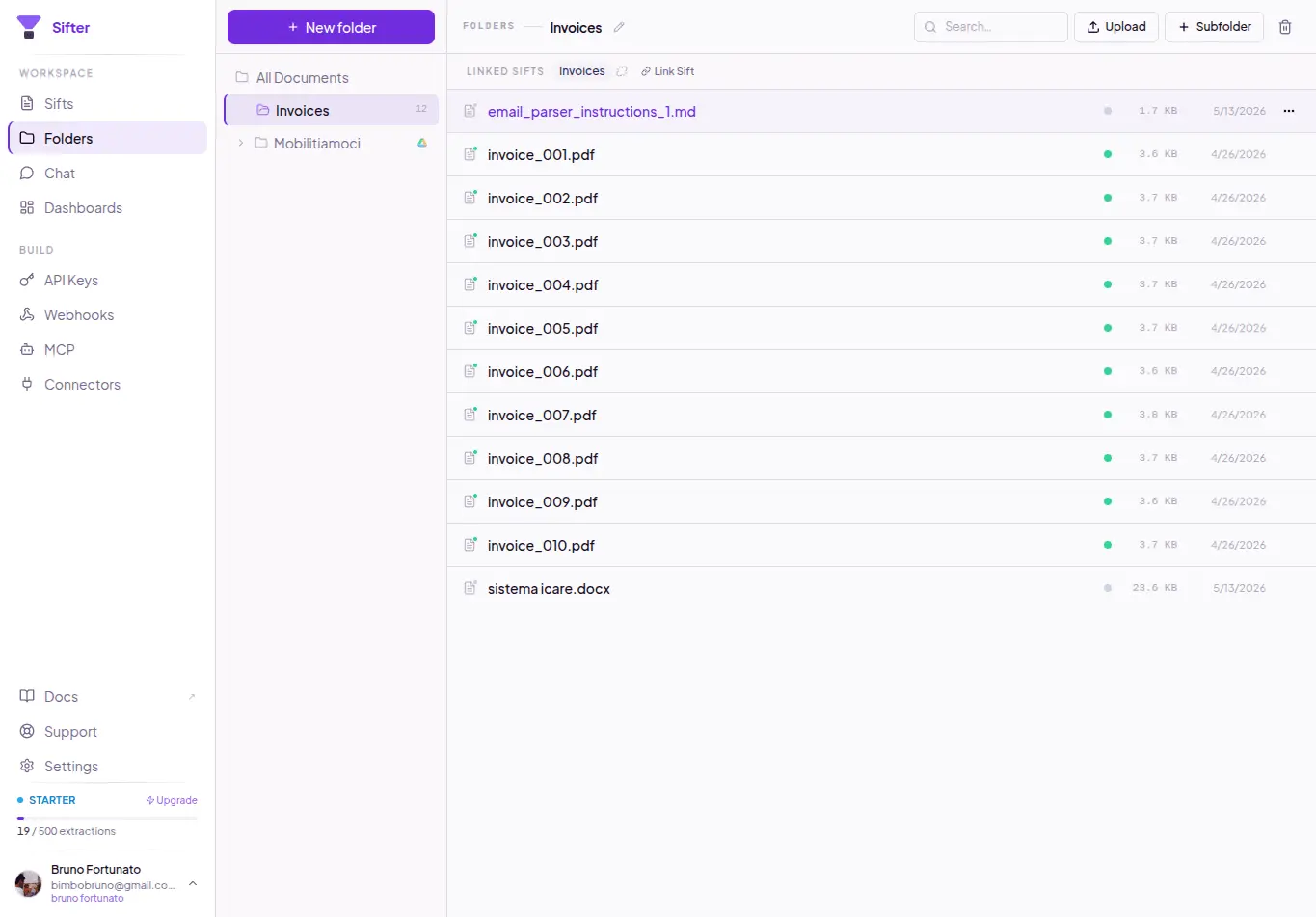
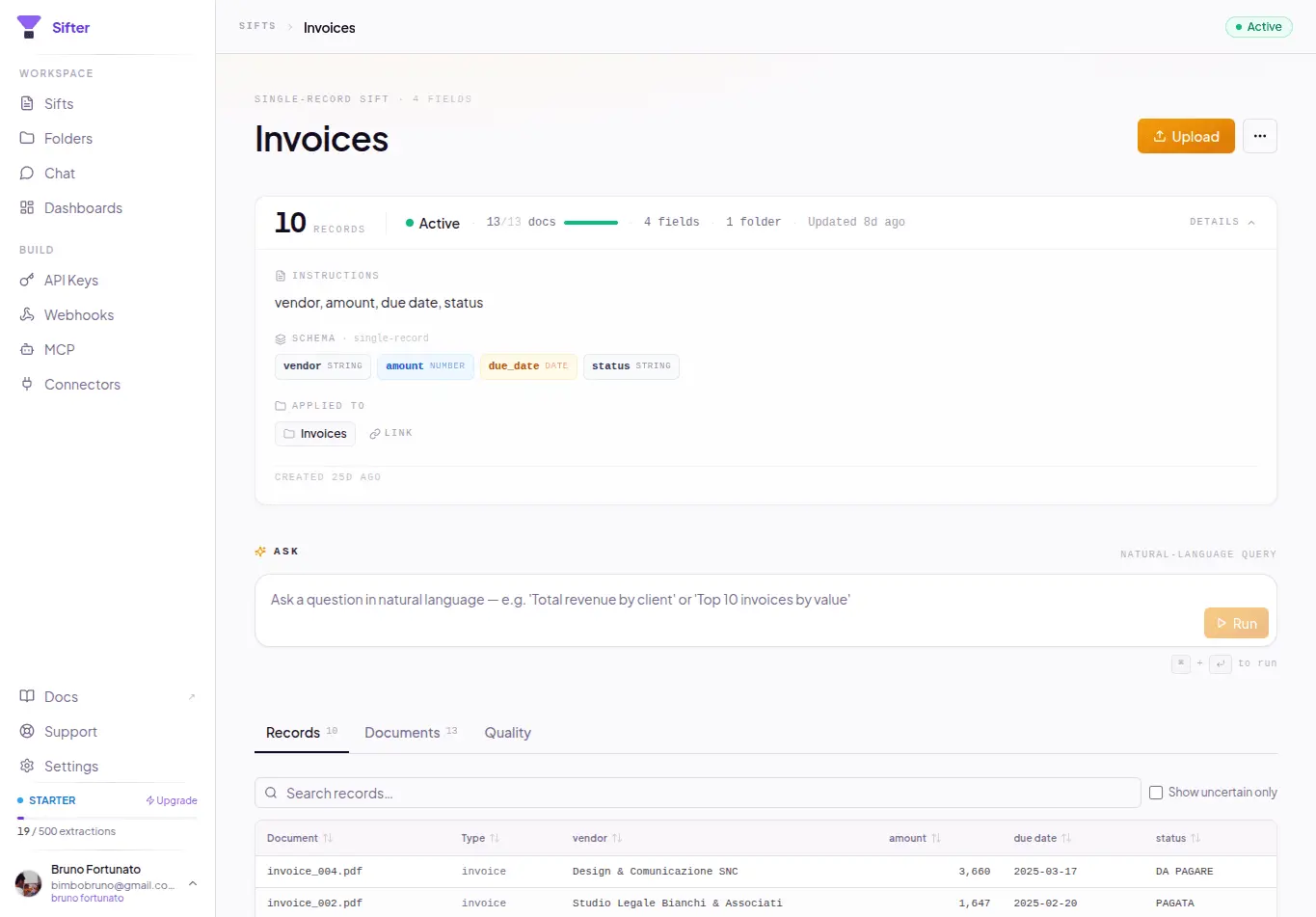
Sifter is an open-source + cloud AI document intelligence platform built around a simple observation: most folders already contain structured data --- it just isn’t represented explicitly. Today, most “AI over documents” systems use a retrieval-first architecture: documents → chunks → embeddings → similarity search. That works well for: * “find this clause” * “summarize this PDF” * “show me the page mentioning X” But many real-world workflows are not retrieval problems. They are aggregation and structured querying problems. Examples: * “show total fuel spend from receipts” * “find contracts expiring in the next 90 days” * “group vehicle photos by brand/model” * “count failed inspections” * “aggregate vendors by category” * “extract all equipment references from technical reports” Humans naturally see latent structure inside collections of files. AI systems usually don’t. Sifter takes a different approach: files → structured records → natural language querying. Users describe in natural language what should be extracted from a collection: * entities * fields * categories * metadata * relationships Sifter then: * infers a schema * processes documents/photos/files * extracts structured records * stores queryable data * enables aggregation and querying in natural language The platform supports multimodal collections including: * PDFs * images * receipts * contracts * inspection reports * operational documents * mixed file collections Instead of just “chatting with PDFs”, Sifter enables workflows closer to: * document intelligence * operational querying * structured extraction * AI-powered data structuring * lightweight agentic workflows Example workflows: * receipts → expense analysis * contracts → expiration/compliance tracking * inspection reports → operational ledgers * vehicle image collections → grouped searchable records * enterprise folders → queryable datasets Sifter is available both as: * open-source (MIT) * managed cloud platform
Product Insights
Sifter is a web-based document intelligence platform available as open-source or managed cloud software. It shifts from retrieval-based search to structured data extraction for operational querying and aggregation across files.
- Supports multimodal files including PDFs, photos, receipts, and technical reports.
- Provides a flexible deployment model with both MIT-licensed open-source and cloud versions.
- Enables natural language querying of extracted structured records for data analysis.
- Automatically infers schemas to transform unstructured collections into queryable datasets.
Ideal for: Data Scientists and Operations Managers can use Sifter to convert unstructured document folders into structured records for compliance tracking, expense analysis, and workflow automation.
Product Video
Watch a video demo of Sifter.
Screenshots
Reviews (2)
Average 5.0 out of 5
Based on 2 reviews
Comments (1)
Built Sifter after repeatedly seeing the same failure mode: RAG is good at retrieval. But many real document workflows are actually aggregation problems. Why Sifter? “group these” “count these”