
OpenMark AI
Benchmark AI models for YOUR use case
Details
- Follow on
- @OpenMarkAILinkedIn
- Categories
- AIDeveloper ToolsAnalytics & Monitoring
- Target Audience
- DevelopersData ScientistsProduct Managers
- Platforms
- Web
- Featured in
- Best A/B Testing Tools
About OpenMark AI
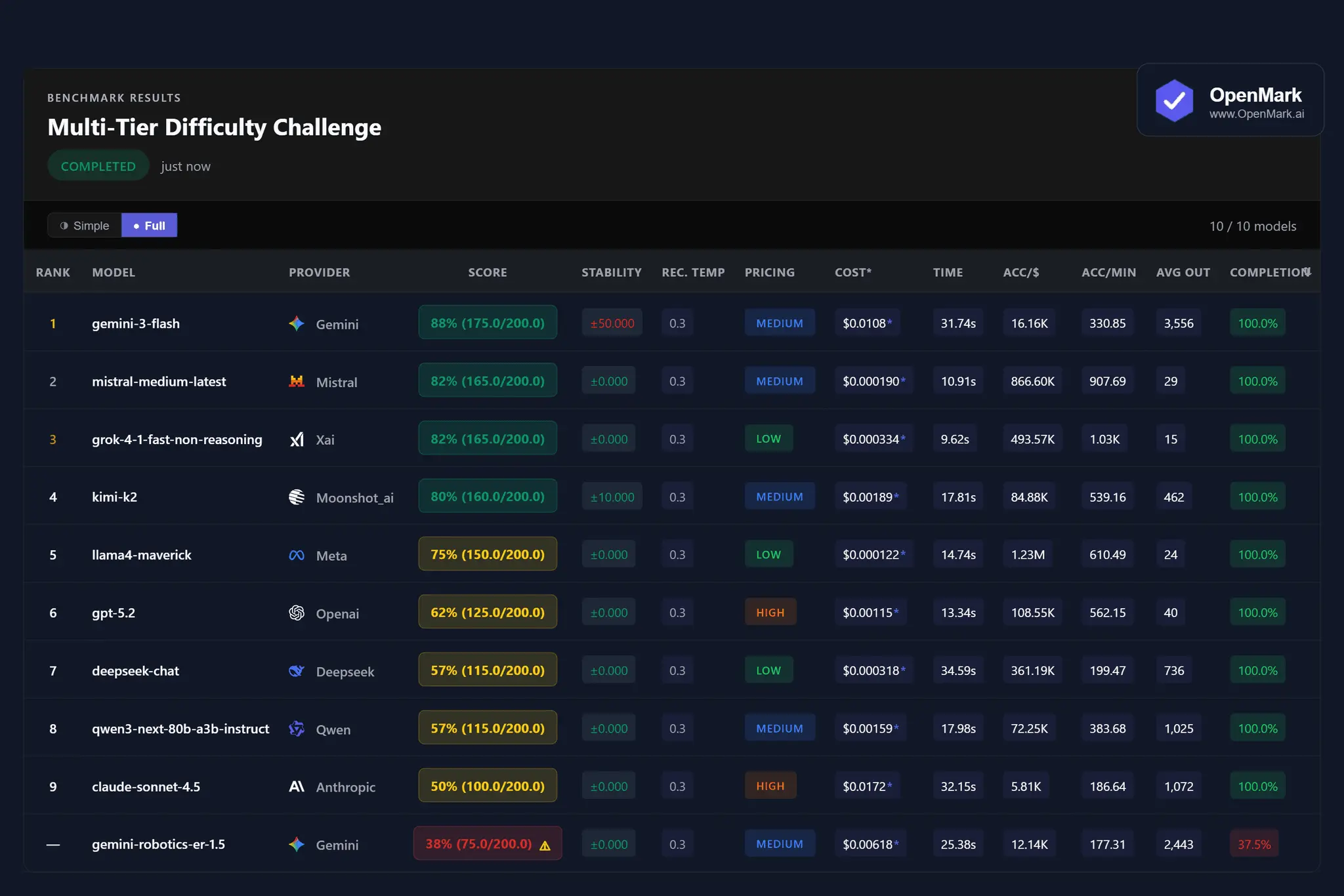
Test ~100 AI models against YOUR specific prompts. Get deterministic scores, real API costs, and stability metrics. Built this after discovering the "best" model for my RAG pipeline was a model that performed better AND cost 10x less. No LLM-as-judge. No voting. Just reproducible results for your actual use case. • 18 scoring modes • Real cost/efficiency calculations from API pricing • Vision & document support • Beginner-friendly yet capable of deep, complex use. Free tier available
Product Insights
OpenMark AI provides a web-based benchmarking environment for testing 100 AI models using deterministic scores and real API cost metrics. It supports vision and document inputs to help users identify the most efficient models for specific RAG pipelines and workflows.
- Supports 18 distinct deterministic scoring modes without relying on LLM-as-judge methods.
- Integrated real-time cost and efficiency calculations based on actual API pricing.
- Native support for vision and document processing across a library of 100 models.
- Accessible web platform designed for both beginner-friendly use and deep technical analysis.
Ideal for: Developers, Data Scientists, and Product Managers who need to validate model performance and stability using their own specific prompts and documents.
Screenshots
Reviews (0)
No reviews yet. Be the first to rate this product!
Comments (2)
This is super compelling, especially the focus on reproducible results and real cost efficiency. Testing models against your own prompts without LLM-as-judge feels like a much more honest way to choose the right model.
Built OpenMark AI after finding a cheaper model beat a 'flagship' one for my task. Stop trusting generic benchmarks, test models on YOUR prompts with deterministic scoring, real costs & 100+ models.
@kean this is very timely. I could have used this when I chose gpt-4o for a client's agentic flow several.months ago, but found out months later that 4.1-mini was performing better for his use case AND much cheaper....
@theaspirinv thank you ! This is verbatim what happened to me 8 months ago. Built a rag pipeline and found out using cheaper models would actually perform better! So i made this benchmarking tool. Now I regularly use it to check for drift.